In this article, we will talk about how our team applied the CQRS and event sourcing approach to an online auction project. We will also cover the results, conclusions, and some hidden pitfalls one should avoid when sticking to this approach.
Introduction
Here is a bit about how it all started. Our client turned to us to work on a platform for timed auctions. The platform was already in production and there was even some feedback, but now the client wanted us to create a platform for live auctions.
An auction, as it is well known, means selling certain items (lots), where buyers, or bidders, place bids. The buyer offering the highest bid becomes the new owner of the lot. With timed auctions, each lot has a predetermined closing time. Buyers place bids, and, at some point, the lot becomes closed. This is pretty much similar to eBay.
The timed platform was designed in a classic way, using CRUD. To close a lot, one had to use a dedicated application with a scheduled start. This app worked very much unreliably, with some bids lost and some made as if on behalf of a different buyer; in addition, some lots could get closed a few times or not get closed at all.
Conversely, live auction delivers an opportunity to participate in a real offline auction remotely on the web. Each auction has a dedicated area (a room) with a host and audience, and there is also a clerk with a laptop, who hits the buttons in the interface and makes the auction go live. The buyers that get connected to the auction can see offline bids and place their own ones.
Both platforms work in real time; however, when it comes to timed auctions, all bidders are in an equal position, while with live auctions, it is extremely important that online bidders should successfully compete with those in the room. In other words, the system must be very fast and reliable. The timed auction platform, meanwhile, had much negative experience, so it was clear to us that the classic CRUD approach was not feasible.
We did not have our own experience in working with CQRS & ES, but, thankfully, our company is large enough, so we were able to get some help from other teams. After we provided the people who were ready to help us with specific information on the matter, we came to the conclusion that CQRS & ES was what we actually needed.
Last but not least, here are some more specifics on online auctions:
- There are many concurrent users attempting to influence the same object in the system, i.e. the current lot. While the buyers place their bids, the clerk enters those bids into the system, closes the lot, and opens the next one. At any given point in time, a single user can place a bid that has a unique value, say, $5.
- You have to store the entire history of system object operations, so that, if required, you may then check who made a particular bid.
- The system response time should be very low, as the online version of the auction must be synced with the offline one, and the users need to understand whether their attempts to place a bid are successful.
- It is important for the users to quickly get information about all changes during an auction, not just about the results of their actions.
- The solution must be scalable, as multiple auctions may be run simultaneously.
CQRS & ES approach: quick overview
Delving into the details of the CQRS & ES approach is definitely out of the scope of this article; you can find a lot of information on the web if you need. However, we will still briefly cover the main points:
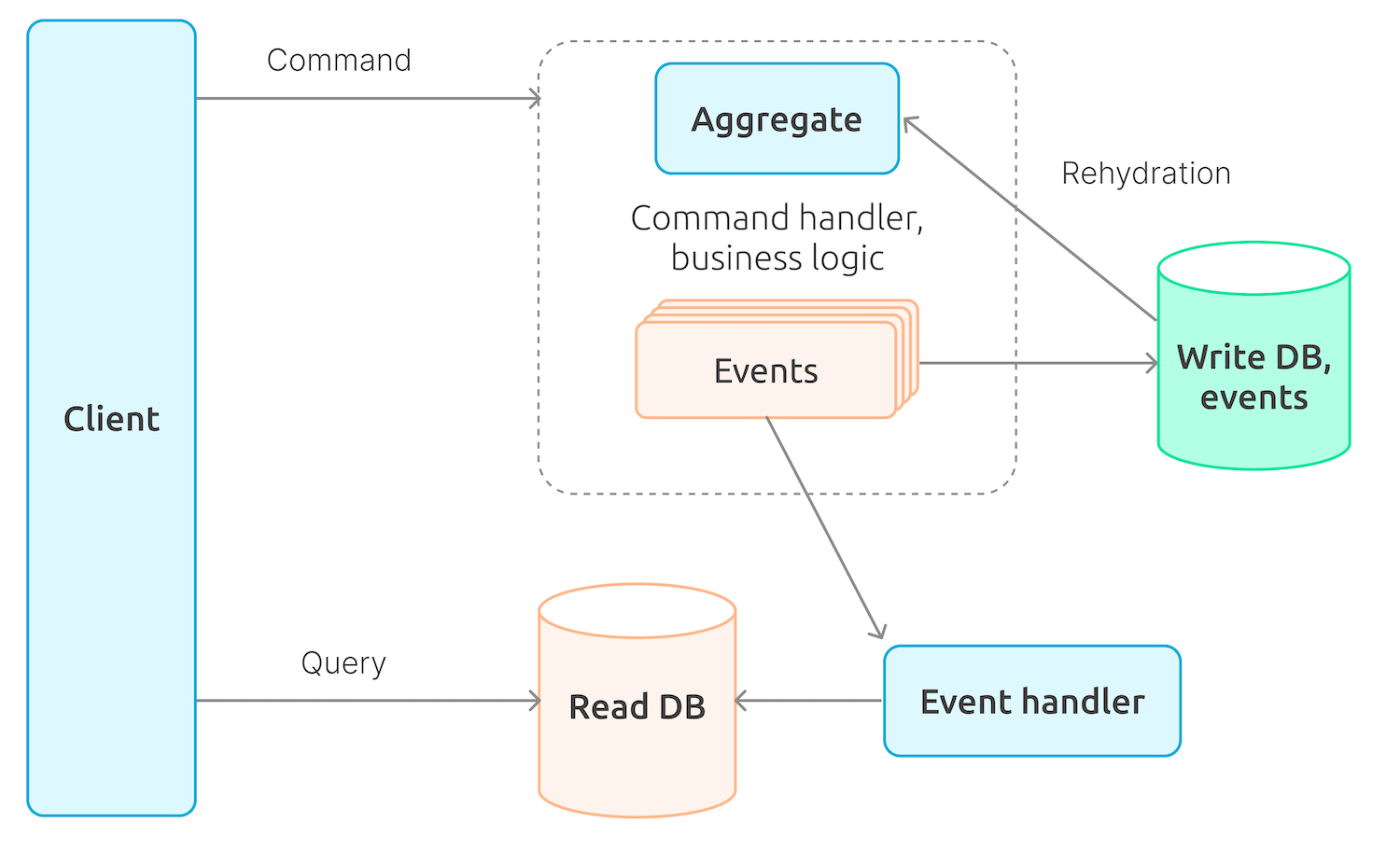
- The most important thing in event sourcing is that the system does not store the data itself; instead, it stores the data change history, i.e. events that lead the system to its current state.
- The domain model is divided into entities called aggregates. Each aggregate has a version, which gets incremented with each event.
- All events are stored in the write database. The events of all system aggregates are stored in a single table in the same order they occur.
- To initiate changes in the system, one has to use commands, with each command being applied to a single aggregate, namely, to its latest, i.e. current, version. An aggregate is built by consistently applying all events belonging to it, which is called rehydration.
- In order not to run the rehydration process every single time from the beginning, some versions of an aggregate (usually, every n version) can be stored in the system as ready-made snapshots. This way, to get an aggregate of the latest version during rehydration, all the system needs to do is apply the events that occurred after the latest snapshot has been created.
- Every command is processed by the system’s business logic; as a result, you get multiple events that are saved in the write database.
- In addition to a write database, the system may also have a read database that stores the data in a form convenient for the system users. Read database entities do not have to absolutely match aggregates within the system. The read database is updated by event handlers.
- Finally, we are getting to the Command Query Responsibility Segregation (CQRS): commands changing the system state are processed by the write part, while those queries that do not change the state of the system are processed by the read part.
Implementation: details and issues
Choosing a framework
In order to save time, as well as due to the lack of specific experience, we decided we needed a framework to work with CQRS & ES.
Overall, our technology stack was based on Microsoft, i.e. .NET and C #, with Microsoft SQL Server as a database, and the system being hosted in Azure. The timed platform used this stack, so it made sense to use the same for the live platform.
At that time, Chinchilla was almost the only option suitable for our tech stack, so we had no other choice but use it.
Why did we actually need a CQRS & ES framework at all? The core reason is that could provide out-of-the-box solutions to work with:
- Aggregate entities, commands, events, aggregate versioning, rehydration, and snapshot features.
- Interfaces to work with various DBMS‘s, saving and loading events aggregate snapshots to and from the write database (event store).
- Interfaces to work with queues: sending commands and events to the appropriate queues, reading commands and events from queues.
- An interface to work with web sockets.
Since we opted for using Chinchilla, we also had to add the following to our stack:
- Azure Service Bus as a command and event bus, as Chinchilla supports it out of the box.
- Microsoft SQL Server for both write and read databases (we had to take that decision rather based on historical context than out of any reasoning).
Meanwhile, the front end part was built with Angular.
As mentioned above, one of the key requirements to the system was that users could find out the results of their own other users’ actions as quickly as possible, which applies to both the buyers and the clerk. Therefore, we used SignalR and web sockets to quickly update the front end data. Thankfully, Chinchilla does support SignalR integration.
Breaking down into aggregates
When it comes to implementing the CQRS & ES approach, one of the first things to do is determine how the domain model will be broken down into aggregates.
In our case, the domain model consists of multiple core entities, such as:
public class Auction
{
public AuctionState State { get; private set; }
public Guid? CurrentLotId { get; private set; }
public List<Guid> Lots { get; }
}
public class Lot
{
public Guid? AuctionId { get; private set; }
public LotState State { get; private set; }
public decimal NextBid { get; private set; }
public Stack<Bid> Bids { get; }
}
public class Bid
{
public decimal Amount { get; set; }
public Guid? BidderId { get; set; }
}
Here, we have two aggregates: Auction and Lot (with Bids). Overall, this makes sense, but there is one thing: with this breakdown, the state of the system is spread over two aggregates. At the same time, in some cases, we have to change both aggregates to maintain consistency: for instance, when an auction is suspended and one cannot place any bids. We could suspend a single lot in question; however, a suspended auction cannot process any commands either, except for Resume.
Alternatively, we could do with just a single Auction aggregate, with all lots and bids within it. However, such an object would be very large, as it may house thousands of lots with dozens of bids per lot. Over an auction’s lifetime, such an aggregate would have a lot of versions, while its rehydration would take quite a long time if there were no snapshots, which was totally unacceptable in our case. Even though we did use snapshots (we actually did), each of them would be too large in case we went this way.
At the same time, to ensure that changes are applied to both aggregates while processing a single user action, one has to either change both aggregates with the same command using a transaction or execute two commands within a single transaction. Both ways are actually not in line with the architecture.
Thus, when it comes to breaking down the domain model into aggregates, one has to take into account the above reasoning.
Currently, we are using two aggregates, Auction and Lot, and break the architecture rules by changing both aggregates with some commands.
Applying a command to a specific aggregate version
In case multiple bidders place a bid on the same lot at the same time, i.e., send a Place a Bid command to the system, only one of the bids will be successful. A lot is an aggregate, which means it has a version. When processing a command, there are events generated, each of them incrementing the aggregate’s version. Here, we’ve got two options:
- Either send a command, indicating the version of the aggregate we want to apply it to. The command handler can then immediately compare the version in the command with the current version of the aggregate and stop its execution if there is a mismatch.
- Or skip specifying any version of an aggregate in the command. This will cause the aggregate to get rehydrated with a certain version, and the business logic will be fine, as the events will still be generated. However, once the events get saved, we may suddenly get an exception saying this aggregate version already exists because someone sent this command before us.
We have to use the second option as, in this case, commands are more likely to get executed. This is because the part of the application sending commands (which in our case is the front end) will probably have an aggregate version that will lag behind the current version on the back end. This is especially true when there are many commands and aggregate versions change frequently.
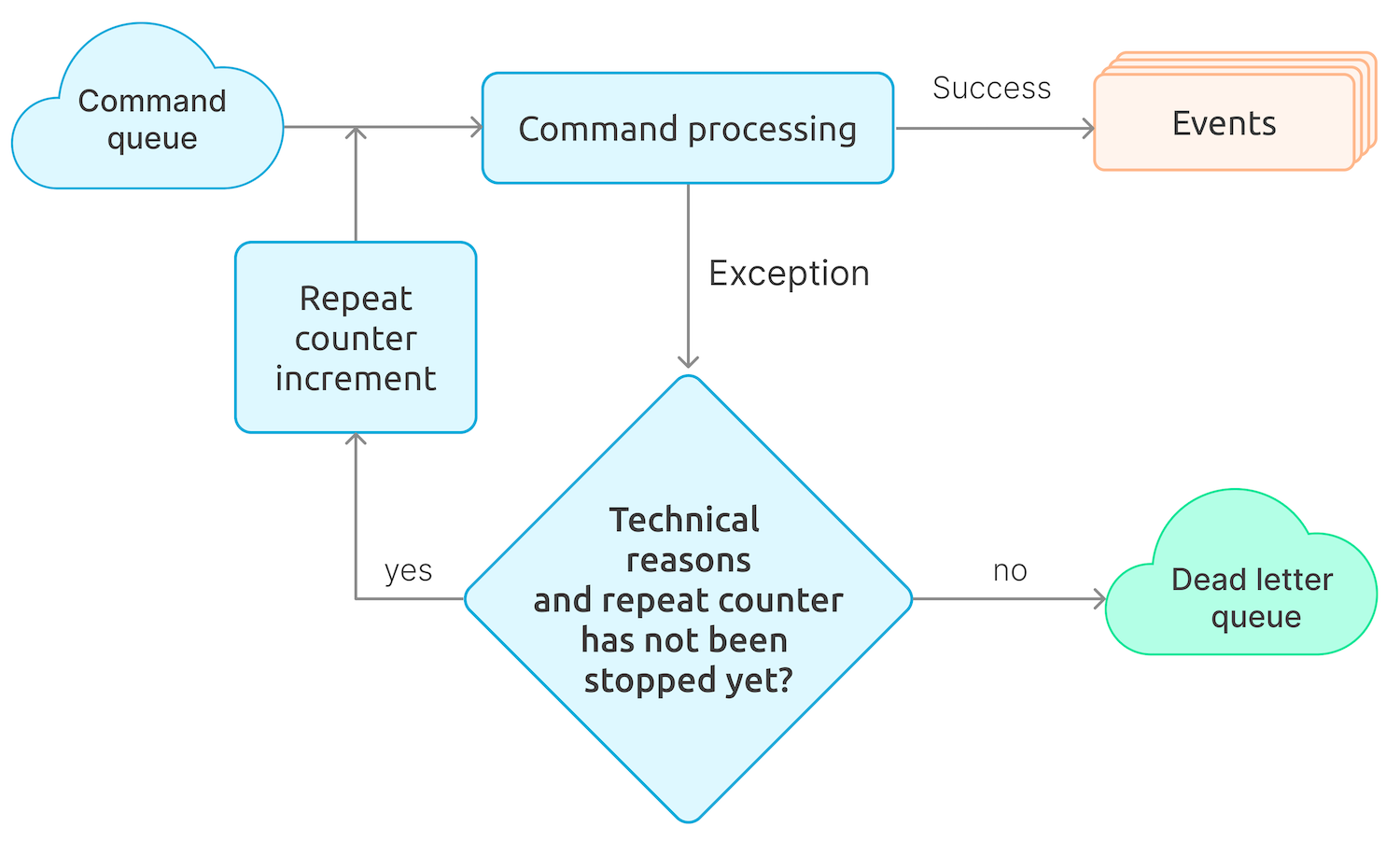
Errors when executing commands in a queue
In our implementation, which heavily relies on Chinchilla, the command handler reads commands from a queue, namely Microsoft Azure Service Bus. We clearly distinguish situations when a command fails for technical reasons, such as timeouts or errors in connecting to a queue or database, and for business reasons, such as attempting to place a bid on a lot with the same amount that has already been accepted. In the first case, the attempt to execute the command gets repeated until the number of repetitions specified in the queue settings is reached, after which the command is sent to the Dead Letter Queue, a dedicated topic for unprocessed messages in the Azure Service Bus. In the second case, the command is sent to the Dead Letter Queue immediately.
Errors when processing events in a queue
Depending on the implementation, the events generated as a result of command execution can also be sent to a queue and taken from the queue by event handlers. When processing events, errors can also occur.
Unlike the case with an unexecuted command, however, this is more complicated. A command may be executed, and the events may get written down to the write database, but the handlers may not be able to process the events. In case any of the handlers attempts to update the read database, this may not go as planned, and the database will be inconsistent. We have of course the repeat attempt function when it comes to processing an event, so the read database will eventually get updated, but there is a risk that it will be corrupted after all those attempts.
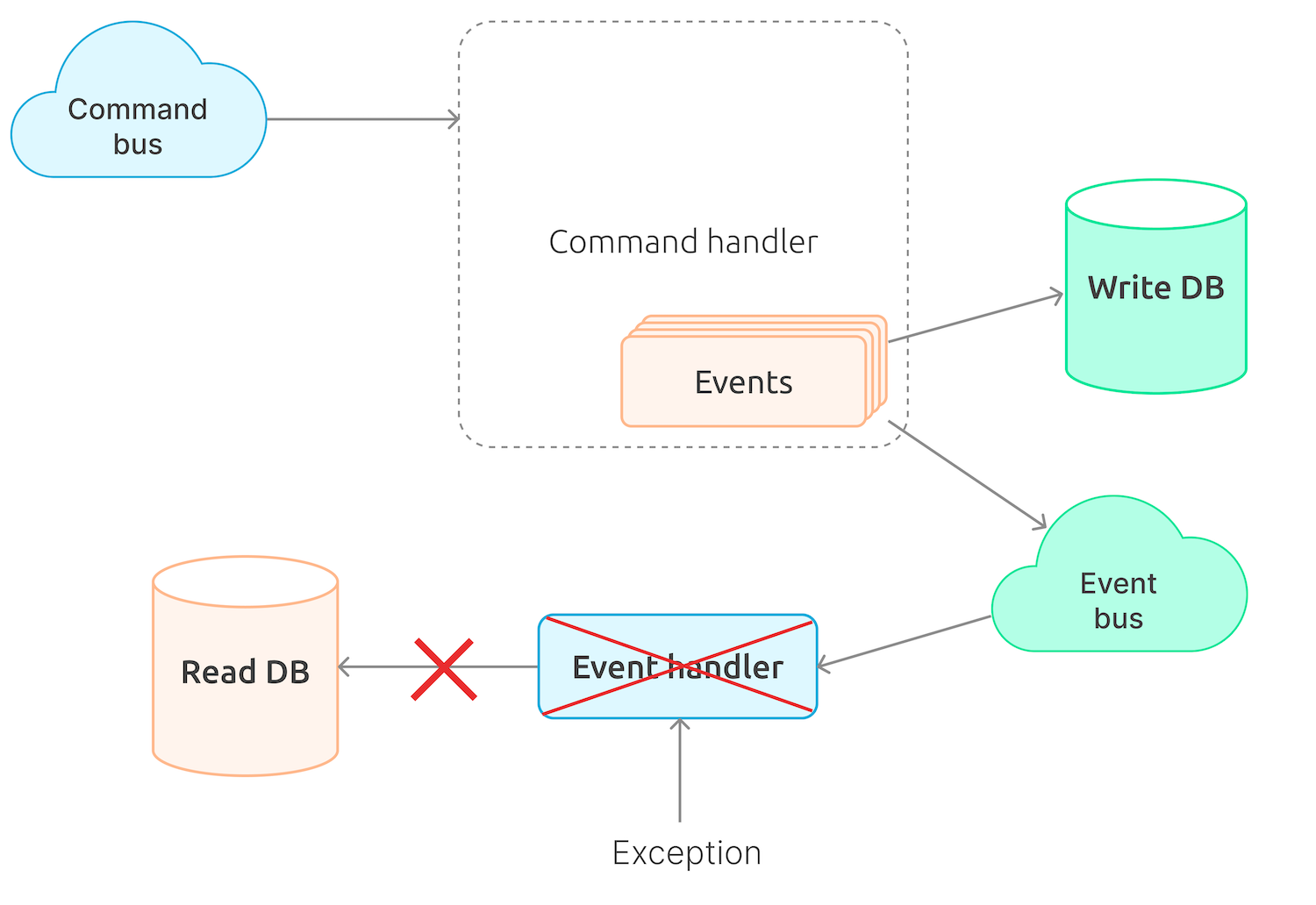
This is exactly the issue we had to face, although, to a large extent, it happened because we implemented such event processing business logic that could fail every now and again in case when there are too many bids being placed. Unluckily, we realized it too late and did not have any chance to change the business implementation quickly and easily.
As a workaround, we for some time stopped using the Azure Service Bus to transfer events from the write part of the application to the read part. Instead, we are currently using the In-Memory Bus, which enables processing both the command and the events within a single transaction and, in case of failure, roll everything back.

Such a workaround is not that good for scalability; at the same time, it helps avoid situations when the read database gets corrupted, resulting in the front end crash, which, in its turn, makes it impossible to continue an auction without re-creating the read database by replaying all events from scratch.
Sending a command in response to an event
Sending such a command is feasible unless failing to execute the second command crashes the system state.
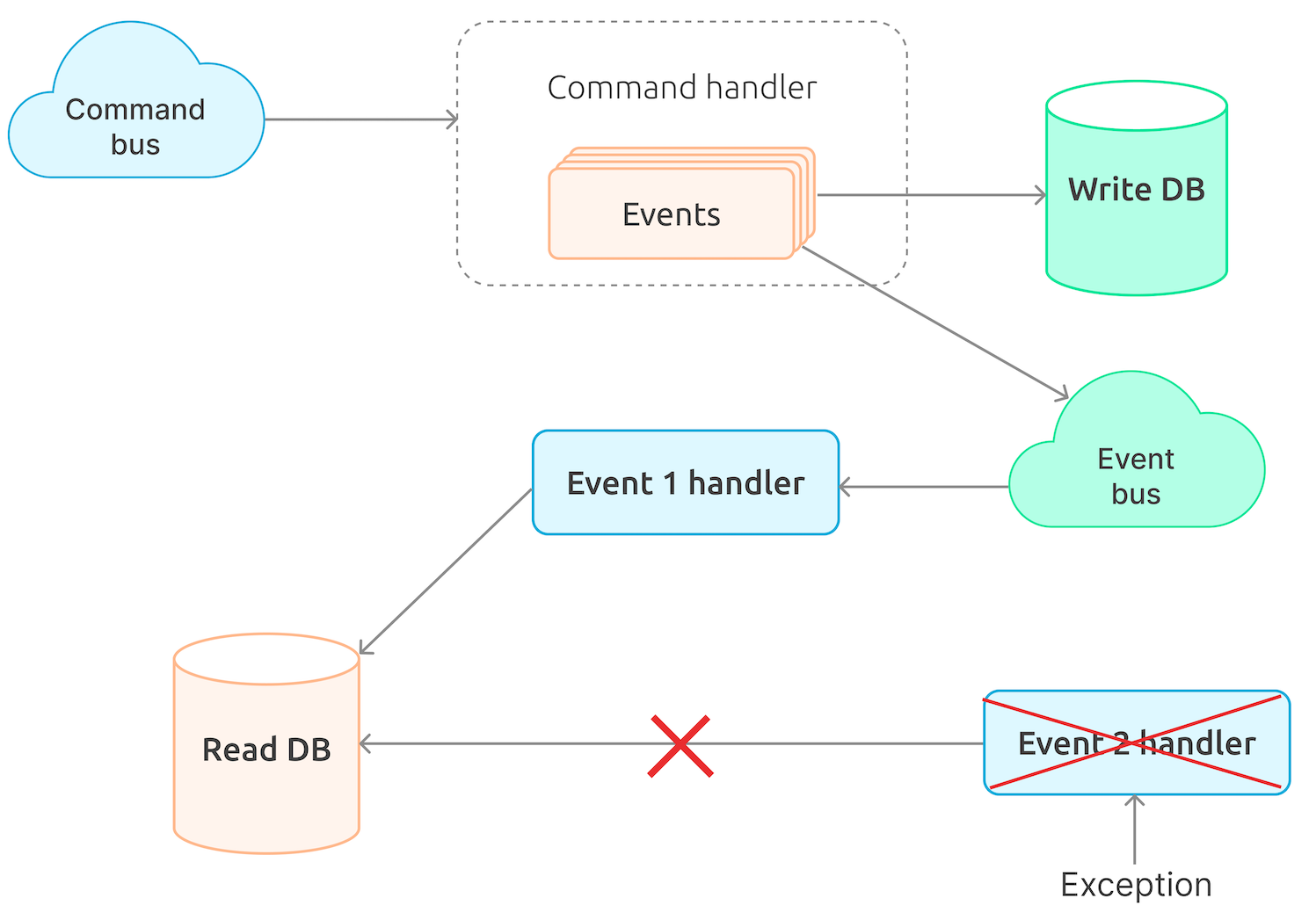
Processing multiple events of a single command
Overall, executing a single command result in multiple events. There are times when a change for each event in the read database is required, while in other cases the event sequence also matters, and in case it is wrong, the events will not get processed appropriately. This means one cannot read the queue and process the events of a single command independently, for instance, using instances of the code that reads messages from the queue. Apart from that, we need to know for sure that the events from the queue will be read in the same order in which they are sent unless we accept that some events of the command will not be successfully processed at the first attempt.
Processing a single event with multiple handlers
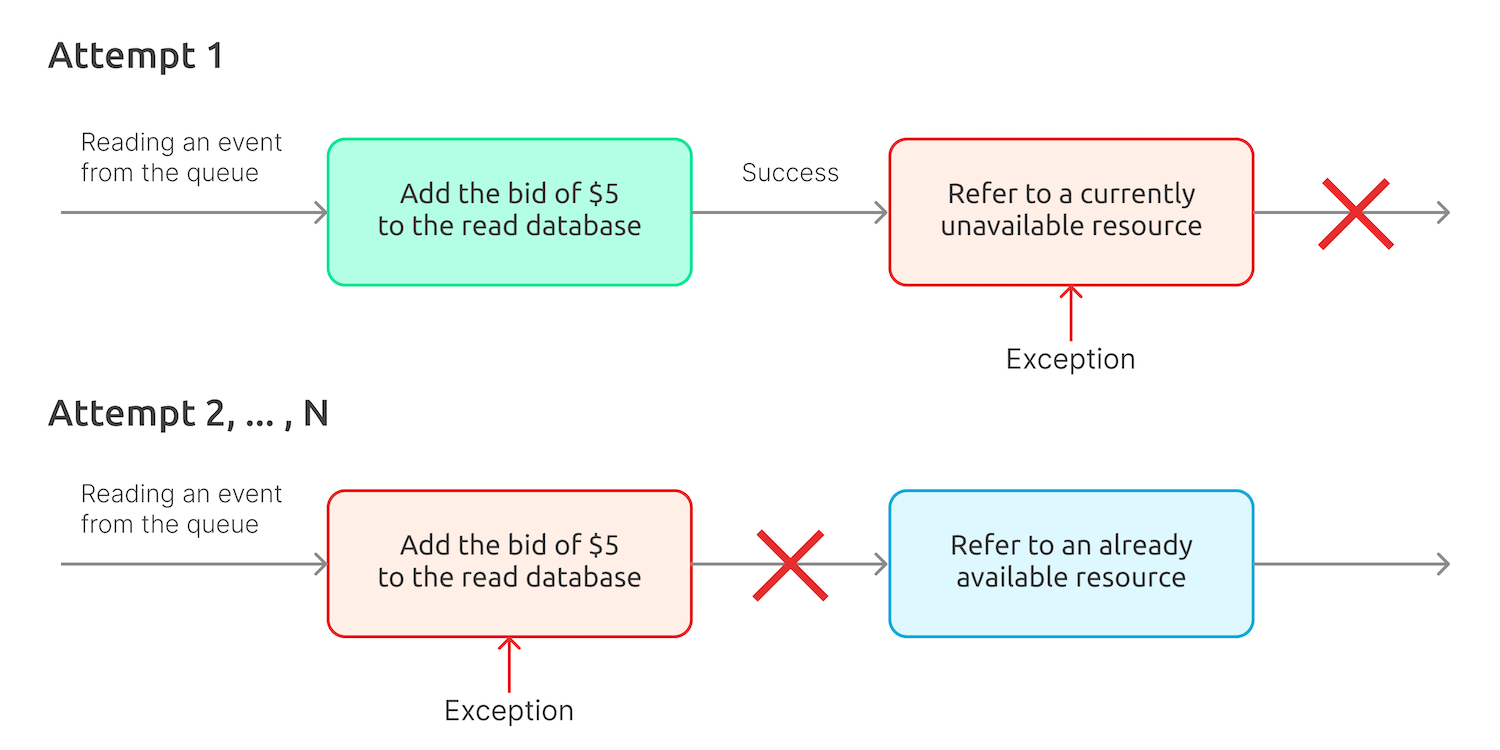
If the system has to perform multiple actions in response to a single event, this, as a rule, requires using multiple handlers, too, which may work both in parallel and sequentially. In the latter case, if one of the handlers fails, the entire sequence is restarted (this is Chinchilla logic). This makes it important that the handlers are idempotent, so that the handler that successfully performed the first run may not fail the second run. Otherwise, when the second handler of the chain will fail and the chain won’t work properly.
Let’s assume an event handler places a $5 bid to the read database. The first attempt is going to be successful, while the second one will fail because of the database constraint.
Summary and conclusion
Currently, our project is at a stage when, hopefully, we have already faced most of the hidden traps and pitfalls relevant to our business-specific cases. Overall, we consider our experience quite successful, with CQRS & ES suiting well our domain. Moving forward, we are also going to stop using Chinchilla and choose another framework that gives more flexibility. Using no framework at all is also an option. We are also likely to make some changes in order to find a balance between the application’s reliability and its performance and scalability.
As for the business aspects, there are still some open questions, for example, in terms of breaking down the domain model into aggregates.
I hope you will find our experience handy, as it will help you save time and avoid hidden pitfalls.