Introduction
Many companies often work with Excel files to store data, and with Excel’s various formulas, they can use it as a super-application. Excel is a great solution to work with numeric data because it provides various functions and features wrapped up into a simple UI.
In most cases of growth, companies want to build business-oriented applications around their data. As an example, we can look at one customer from the construction area. This customer uses Excel files to store a lot of information about products, including prices, parameters and other support information.
Excel contains many formulas and complex algorithms that are continuously improved by engineers (not programmers) and used as solutions to calculate prices and characteristics for product blueprints and provide this information to clients. Suppose we need to build an application that can use these Excel files to improve communication between the company and its clients. This application should provide various kinds of advantageous features, such as parameter optimisations. Therefore, we have the following requirement for a new web application from the customer:
- The web application should work with Excel files because all data are presented in that format, and they may need to be periodically changed by internal experts;
- The web application should provide calculation results without delay;
- The solution must be scalable, flexible and extendable for use in parameter optimisation tasks.
In this post, we look at existing libraries to create performance tests for each solution. In most cases, existing solutions cannot be used in performance-critical areas. Thus, we dive into code generation and investigate a new approach to improve Excel calculation performance.
Existing solutions
Let us start with a search for existing solutions that can handle Excel files. The key requirements for a solution are that it must:
- Support Excel reading with all data and formulas;
- Support Excel formula calculations;
- Have a transparent and simple license for commercial use;
- Have an understandable documentation and large support community.
| Library | Link | Documentation | Licence |
|---|---|---|---|
| EPPlus 4 | github | github wiki | GNU Library General Public License |
| EPPlus 5 | github | github wiki | Polyform Noncommercial License 1.0.0 (License Overview) |
| NPOI | github | github wiki | Apache License 2.0 |
| Spire | e-iceblue.com | e-iceblue.com Tutorials | License Agreement |
| Excel Interop (Microsoft.Office.Interop.Excel) |
n/a | docs.microsoft.com | Installation of MS Office required on each machine where solution will be used |
Performance testing
Performance testing is required to validate the existing solutions and measure each of their metrics. We highlight a few key metrics: initialisation time, execution time for one iteration, accuracy and SD (standard deviation), and error rate during testing. To calculate accuracy and SD, we use Excel Interop results as a reference. This means that the SD and accuracy metrics for Excel Interop library cannot be measured.
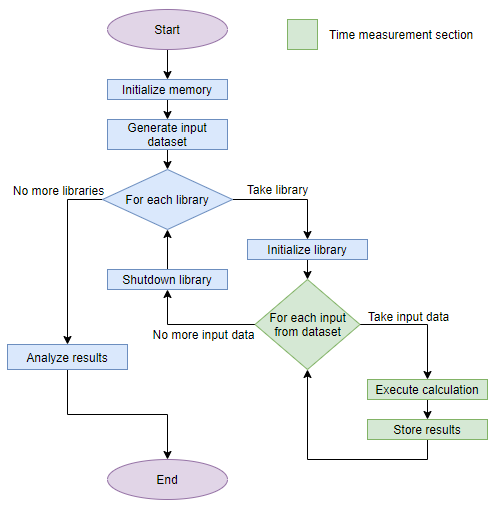
We built a special Excel file including complex formulas with many dependencies and math functions that should be used for testing. We generate 10,000 data vectors of input parameters to run tests and measure the metrics.
| Metrics | Native | EPPlus 4 EPPlus 5 |
NPOI | Spire | Excel Interop |
| Time to initialise (ms) | 0 | 241 | 368 | 722 | 1640 |
| Avg. time per iteration (ms) | 0.0004 | 0.9174 | 1.8996 | 7.7647 | |
| Standard deviation | 0.035884 | 0.0 | 0.0 | 0.0 | n/a |
| Accuracy | 98.79% | 100.0% | 100.0% | 100.0% | n/a |
| Error rate | 0.0% | 0.3% | 0.3% | 0.28% | 0.3% |
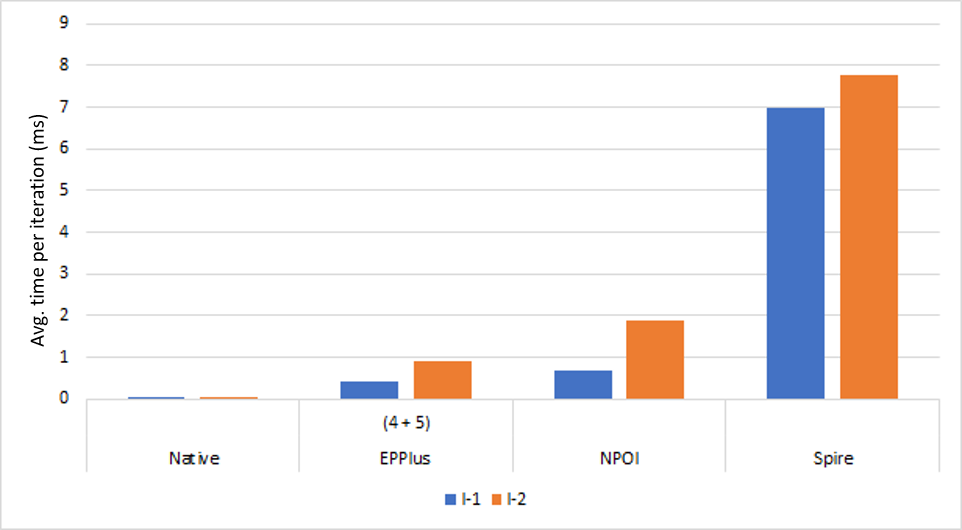
As you can see in the table and picture above, the Excel.Interop solution is very slow and is not applicable for production solutions. Other libraries have better results, but they are still relatively poor in comparison with native formula implementation. The winner with the best results out of all the libraries is EPPlus.
Code generation solution
When we talk about highly scalable and highly loaded applications, we should use solutions that provide maximum performance. Our key goal is to build a solution that can calculate formulas from Excel sheets, so the oblivious approach to improve performance is to traspile Excel formulas from source sheet to native C# code and use it directly without having to access the Excel libraries every time. Code generation should help us with this.
The code generation solution is an approach based on the auto-generation of any code source based on input data to solve a particular task. In the case of Excel formula computation, this means that we should transpile the Excel formula to C# code and compile it in runtime to make it usable in the required business application. To achieve this, the following steps are required:
- Read formulas from input Excel file;
- Parse formulas to tokens and AST nodes;
- Build a cells dependency tree based on the formulas;
- Transpile all dependent formulas to C#;
- Compile generated C# code to assembly;
- Load and attach generated assembly;
- Use exported functions from loaded assembly and pass any inputs to obtain results as soon as possible.
For a quick start, we use the EPPlus library to read formulas from the Excel file and begin an initial tokenisation process. Actually, this library already allows for the implementation of expression tree building. However, this implementation does not have a full and transparent API on hand for use in different areas. Therefore, we just start from the formulas already parsed to tokens and transpile that to the C# equivalent. The key challenge is building a correct implementation of Excel-compatible functions.
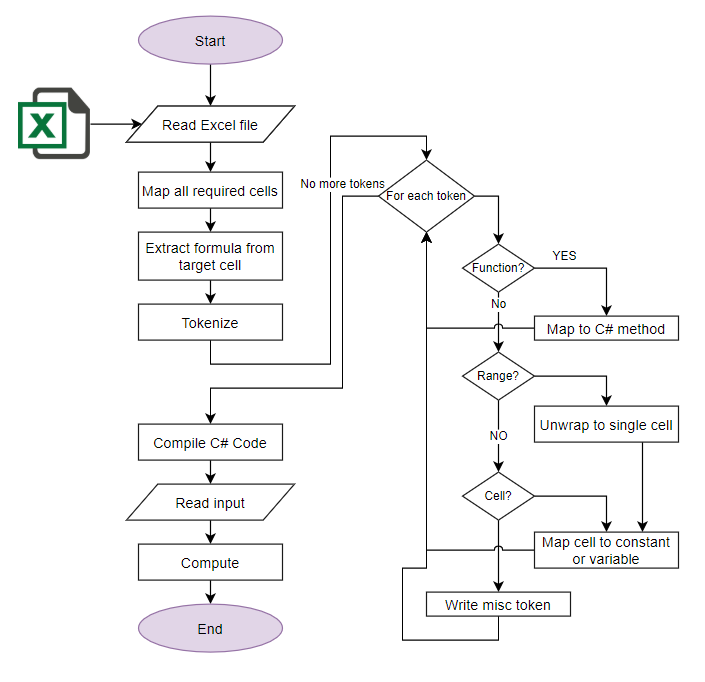
As a result, we have a library that can transpile Excel formulas to the C# method. The name of this solution is ‘EPPlus Compiled’. The results of a new performance test run demonstrate that performance has increased 300 times compared with the standard implementation of Excel formula calculation in the EPPlus library.
In the development of this solution, we have done a lot of work, so we will save some things for the next time:
- At this time, we don’t optimise AST to prevent computation duplications of the same data. Our manual pre-tests show that this kind of optimisation can also improve performance in some cases.
- Some complex algorithms and functions that use a cell range can be improved. For example, inlining of loops for cell ranges can be used instead of loops and other functions, which could improve performance;
- In Excel, all constants (e.g., the PI value) are presented as functions, so in our solution we also use wrapping functions that provide constants values. Changing this logic to inline constants could also lead to performance improvements;
Summary
In summary, we solved a complex task, and the performance of the Excel calculation formulas is now 16,906 times better than that of the Excel Interop library, and 300 times better than that of the EPPlus library. We then wrote a solution to transpile Excel formulas to C# code.
| Metrics | Native | EPPlus Compiled | EPPlus 4 EPPlus 5 |
NPOI | Spire | Excel Interop |
| Time to initialise (ms) | 0 | 239 | 241 | 368 | 722 | 1640 |
| Avg. time per iteration (ms) | 0.0004 | 0.003 | 0.9174 | 1.8996 | 7.7647 | 50.7194 |
| Standard deviation | 0.035884 | 0.0 | 0.0 | 0.0 | 0.0 | n/a |
| Accuracy | 98.79% | 100.0% | 100.0% | 100.0% | 100.0% | n/a |
| Errors rate | 0.0% | 0.0% | 0.3% | 0.3% | 0.28% | 0.3% |