In this article, we will talk about an example of a system for transferring text from paper documents into electronic form. We will look at two main stages: (1) the selection of areas with text on scans of documents, and (2) character recognition in these selections. We will also pay attention to the difficulties that can be encountered (along with the ways of resolving them) and present some options for system development.
The primary conversion of a document into electronic form consists of its scanning or photographing, which results in a graphic file in the form of a photo or scan. However, such files, especially high-resolution ones, take up a lot of disk space and cannot be edited. In this regard, it is advisable to extract text from graphic files, which can be successfully completed with optical character recognition (OCR).
About OCR and its goals
OCR is the conversion of images of typewritten, handwritten, or printed text into electronic text data. OCR data processing can be used for a variety of tasks:
- data extraction and placement in an electronic database of banking, accounting, or legal documents
- scanning of printed documents with subsequent editing
- transfer of historical documents and books to archives
- distribution of printed material by topic
- indexing and searching of scanned printed material.
Processing large volumes of documents using ready-made commercial OCR solutions often leads to high costs and low productivity. This is due to restrictions on the volume of processed documents. Therefore, it is necessary to develop your own system that can be used for organizations such as banks, real estate companies, universities, and other organizations that work with large volumes of paper documents. As an example, let's consider a single system based on the pipeline principle (OCR pipeline), in which the following operations are performed sequentially:
- loading a scan of a document
- extraction of words and lines from a scan
- character recognition in words and lines
- formation of an electronic document.
Word and line extraction
Before character recognition of the image with the document, it is advisable to extract the words and lines of text. There are two main approaches through which this can be done: neural nets and computer vision. Let's look at each one of these in more detail.
Recently, neural nets have been increasingly used to detect words in images. Using the ResNet family of networks, you can select rectangular frames of text. However, if the documents contain many words and lines, then the network data can be quite slow. Computational costs in these cases significantly exceed the cost of using computer vision methods.
In addition, ResNet models have a complex architecture and are more difficult to train for this task. This is because they are designed to classify images and detect only a small number of blocks of text. Using them would significantly slow down pipeline development and, in some cases, reduce performance. Therefore, it is necessary to turn instead to methods of line detection using computer vision. More specifically, we will focus on the method of maximally stable extremal regions (MSER) [1].

Figure 1. Examples of MSER detection of lines in documents
During MSER detection, the text in the binarized scanned image is initially ‘smeared’ into spots. Based on the subpixel calculations, the resulting spots are limited to connected areas and enclosed in rectangular frames (Figure 1). In this way, the source data is compressed, and images containing the words and lines are extracted from the scanned document. It is worth noting that this method does not depend on the colour of the extracted text. It is only important that it is sufficiently contrasted with the background.
OCR AI
The next step after MSER extraction of images with text is character recognition in them. Recently, AI research has shown that character recognition in images is most successfully performed on the basis of deep machine learning. Neural networks containing many levels (i.e., deep neural networks) are used, which are able to accumulate features and representations in the processed data.
Training data generation
Deep learning neural networks usually require large amounts of training samples for high-quality recognition. The manual mark-up and collection of training data is time-consuming and requires a lot of effort, so ready-made datasets are used more often, or already-marked data are synthetically generated. When creating training samples, it is important to use both high-quality lines and lines with various effects and distortions when scanning. As a result, it is possible to increase the resistance of the OCR system to distortion.

Figure 2, a. Generated strings

Figure 2, b. Strings from UW3 dataset
As a training sample, consider a University of Washington (UW3) dataset that consists of more than 80K lines of scanned pages with modern business and scientific English (Figure 2, b). To complicate matters, the set of geometric and photometric distortions as well as the set of fonts used in the lines are insufficient. Therefore, it is necessary to supplement the training sample with generated lines. This can be done using an automatic generator of text lines of different fonts, colours, backgrounds, etc (Figure 2, a). You can use 10 of the most popular fonts found in documents. These include Times New Roman, Helvetica, Baskerville, Computer Modern, Arial, and others.
More versatility regarding fonts can be achieved by using information from the Font Map (Figure 3). This map describes the relative position of the fonts, so you can then determine their similarity. In other words, the closer two fonts are to each other, the more similar they are. To retrain the network, several fonts are selected in the map that are the most remote from those that the model has already been trained on.
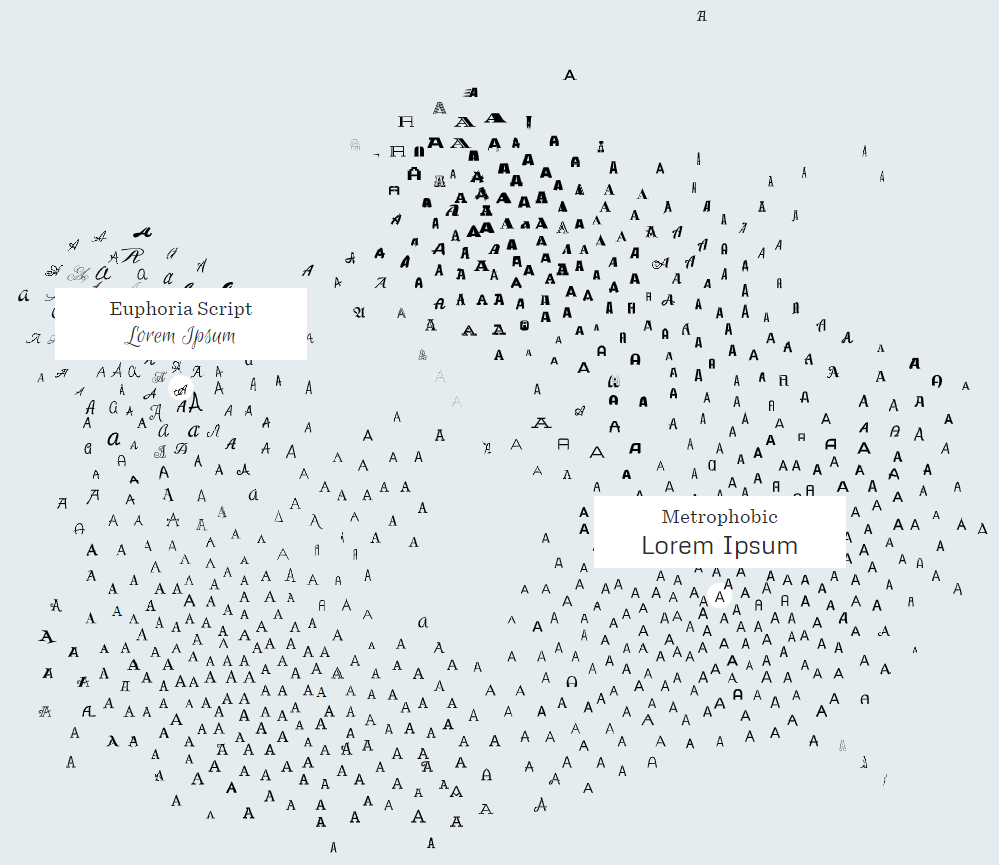
Figure 3. Font Map http://fontmap.ideo.com
CNN architecture
Input data for training and network recognition are parts of scanned images with strings or words extracted during the MSER detection. Output data are ordered sets of characters that form text in electronic format.
CNNs, or convolutional neural networks [2], are effectively used for character recognition in images, forming representations of parts of images similar to the human visual system.
A CNN is usually an alternation of convolutional and pooling layers, which are combined in convolutional blocks and fully connected layers at the output (Figure 4). In the convolutional layer, weights are combined into so-called feature maps. Each of the neurons of the feature map is connected to a part of the neurons of the previous layer.
CNNs are based on mathematical convolution operations and subsequent dimension reductions (pooling) using threshold functions that exclude negative weights. After all transformations in convolutional blocks, feature maps are concatenated into a single vector (concatenation) at the input of a fully connected network. Let's look at the operations of convolution and dimension reduction in more detail.
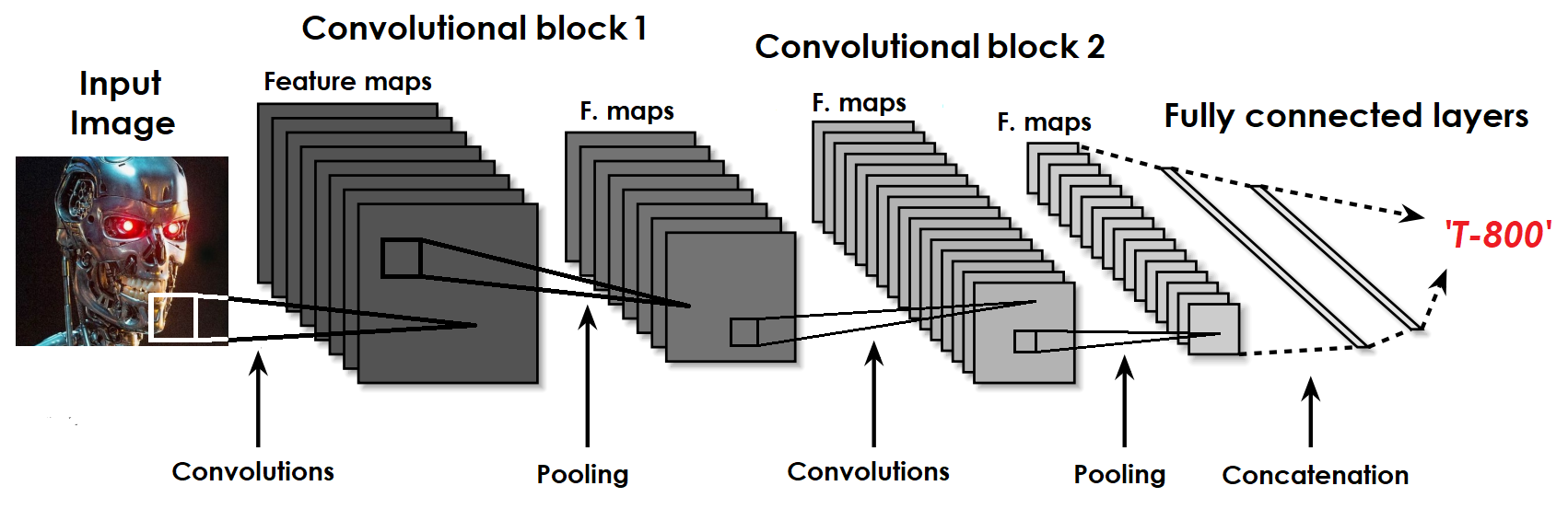
Figure 4. CNN mechanism
Convolutional network computing
In the convolutional layer, the input source image or map of the previous convolution block (input data) is subjected to a convolution operation using a small matrix (convolution kernel) (Figure 5). In the calculations, the convolution kernel moves along the input data matrix. Output data are represented in a matrix consisting of the values of the sum of pairwise products of the corresponding part of the input data with a convolution kernel. The figure below shows an example of a convolutional layer with a 3X3 convolution kernel.
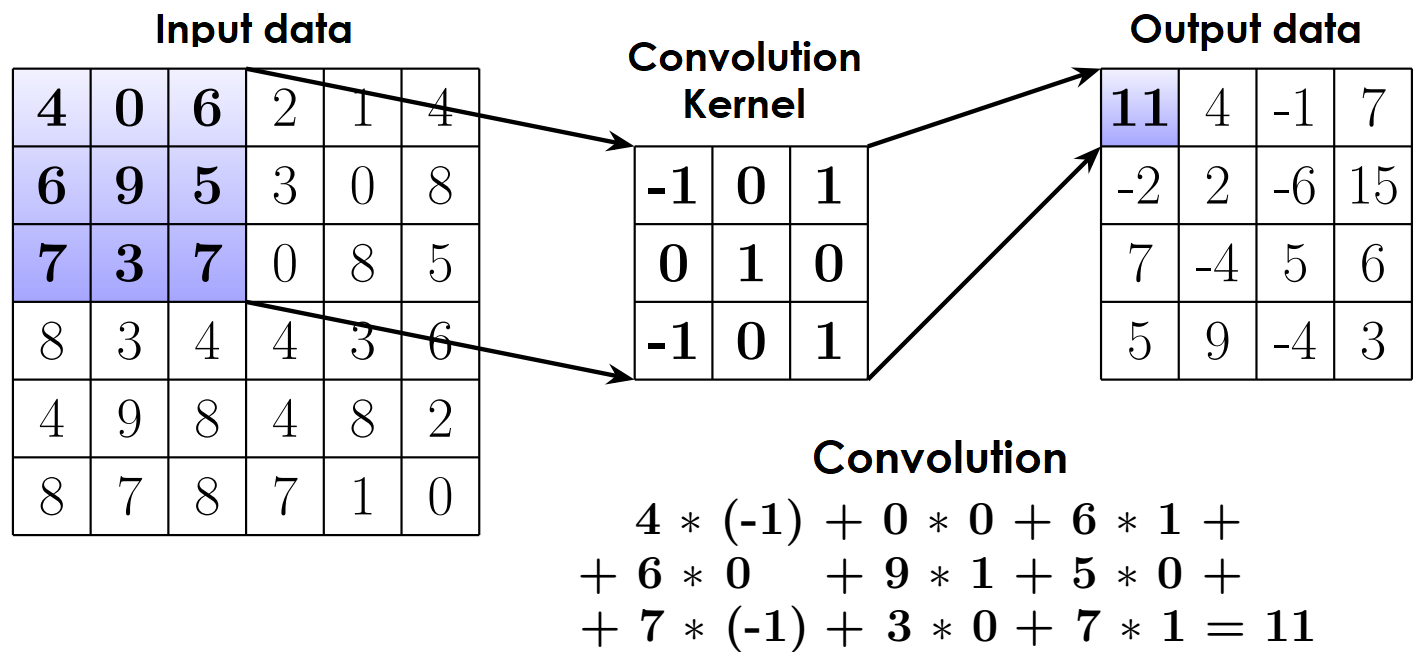
Figure 5. Convolutional layer
In the pooling layer, the dimension of the output of the convolutional layer is reduced in two steps (Figure 6):
- The use of the neural activation function (ReLU). The most frequently used activation function in CNNs is ReLU, which replaces negative values in the matrix with zeros. Recently, two of its variants have proven to be effective. The first is the noisy ReLU, which replaces negative values with zeros and adds a small random term to positive values. The second is the leaky ReLU, which replaces negative values with random numbers instead of zeros.
- Reducing the dimension. The matrix obtained after activation is divided into cells in which the values are aggregated. This can be done in different ways, but the max-pooling method is often used
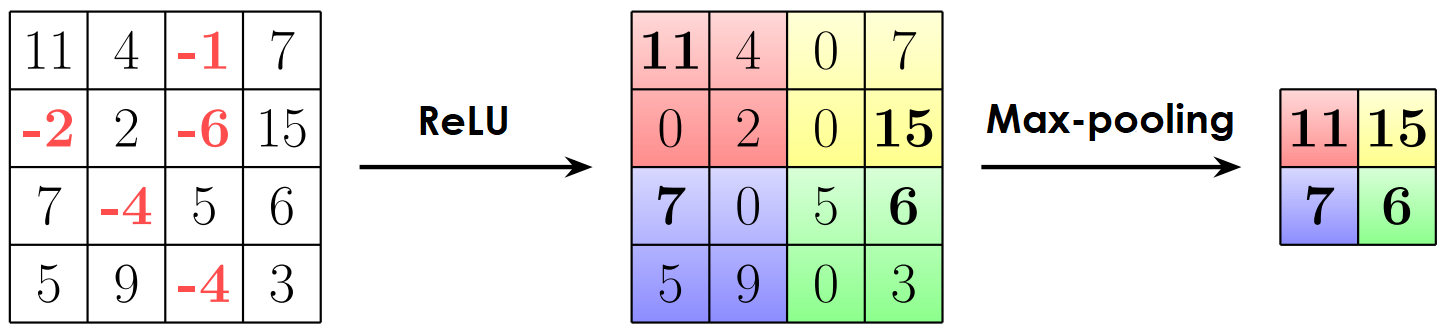
Figure 6. Pooling layer
The figure above shows an example of a pooling layer using ReLU and max pooling. Output values are passed to the input of the next convolutional block or pulled into a vector for a fully connected layer if there are no more convolutional blocks.
Network architecture for OCR
In our case, convolutional blocks alone are not enough. This is because large amounts of data must be processed, and it is necessary to consider the sequence of characters in lines. Therefore, we can use a hybrid architecture consisting of the following (Figure 7):
- CNN blocks that extract representations from images
- blocks of long short-term memory (LSTM) [3], each of which consists of a complex of threshold functions that allow for the memorisation of representations for both long and short periods of time; they also prevent the premature ‘forgetting’ of representations during training
- CTC classifier [4], which helps to preserve the sequence of output characters.
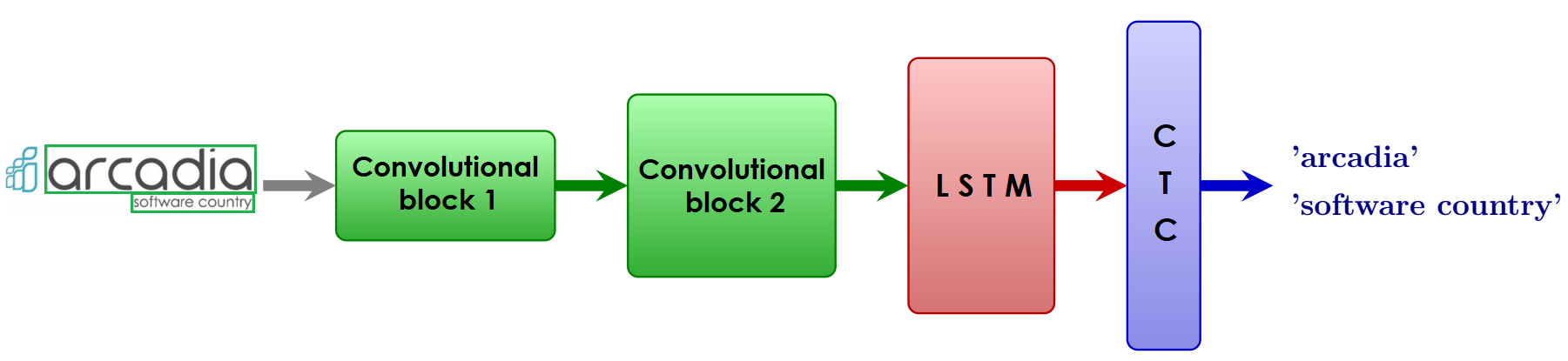
Figure 7. Neural network of CNN, LSTM, and CTC blocks for OCR.
Computational experiments
In the course of training, we performed a series of experiments on sets of lines in the training samples. Let's highlight the main ones: (1) those based only on generated lines (10 most popular fonts + 10 fonts from font map), (2) those based on generated lines with the three most frequently used fonts in documents (Times New Roman, Helvetica, and Computer Modern) with lines from the UW3 dataset, and (3) those on based on generated lines (10 + 10 fonts) with lines from the UW3 dataset (Table).

Table. Network training experiments
Note that by the end of the iterative process, the maximum accuracy in the validation sample is almost the same. On the contrary, the accuracy values of the test sample differ significantly, as adding rows from the UW3 dataset to the generated rows increases the recognition accuracy. However, increasing the fonts in the synthetically generated strings also slightly increases the recognition accuracy.
The neural network is trained according to the ‘early stop’ principle: after a certain number of iterations, a randomly selected subset of lines from the training sample (validation sample) is recognised. If the maximum accuracy value does not change during several such checks, then the iterative learning process is stopped, and the weights of the neural network for recognising strings from documents are saved. The learning time is calculated from the start of the iterative process to the stop. We would use Nvidia GPUs of the Tesla family (K8 and V100) for this process.
We consider documents with a scanning resolution of 96 dpi in English. The text can be different colour, thickness or leading. The built architecture allows us to achieve an accuracy of character recognition up to 95–99%.
Thus, as output, we get characters combined into words or strings that form electronic documents.
Pipeline
Significant acceleration of document processing is achieved by organising the recognition system on the principle of a pipeline with minimal downtime (Figure 8). This process also involves parallelising calculations in the CPU and GPU in conjunction with the rational use of memory. Docker and Kubernetes are used to deploy such systems.
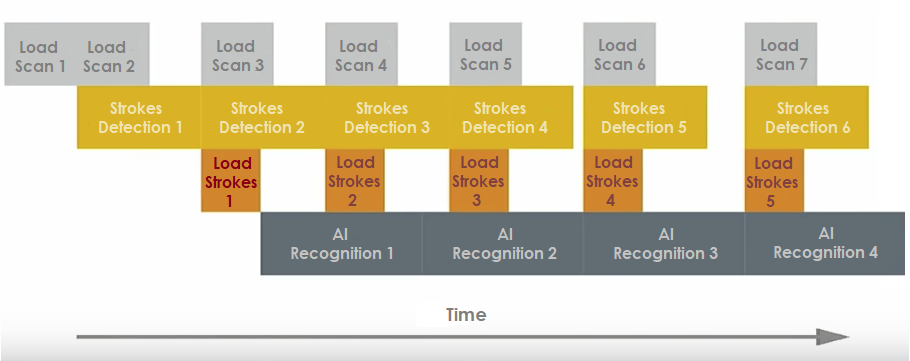
Figure 8. Organisation of the OCR AI recognition system based on the pipeline principle.
The length of the rectangular blocks describing the processing procedure schematically corresponds to the time interval. The execution time for each procedure may vary depending on the number of characters in the document.
Load Scan i—loading the scan of the i-th document,
Strokes Detection i—extracting lines from the i-th document using MSER,
Load Strokes i—OpenCV preprocessing and normalisation of the extracted lines of the i-th document along with loading to the network input,
AI Recognition i—character recognition in the lines of the i-th document based on the built deep network.
To improve the quality of MSER detection, mathematical methods of digital image processing are used, which, among other things, exclude unwanted noise that naturally occurs when scanning paper documents. When implementing image processing and the MSER detection of words and lines, it is convenient to use the Python language via the OpenCV computer vision library.
To improve the quality of training, protection against overfitting, and subsequent recognition in the AI neural network, adaptive updating of the network weights [5], dropout decimation [6] and batch normalisation [7] are used. When implementing a deep learning neural network for production, it is advisable to use one of the Tensorflow or Pytorch frameworks. Nvidia GPU computing is supported using CUDA and CuDNN technologies.
Additional performance gains can be achieved with the help of TensorRT technology [8], which is designed for optimal use of network weights when computing in GPUs produced by Nvidia (e.g., Tesla or k8). The weights of the trained models are converted to a more compressed floating-point format. This allows for a computing speed that is more than 40 times faster in the GPU compared to the CPU without any visible loss of recognition accuracy.
What's next?
Let us highlight several directions of development for the considered system.
- Scanning can be done in different ways and at different angles. Therefore, the system can be supplemented with a document border and corner detector. Intelligent filtering can also be introduced to improve the quality of the scan.
- We analysed the data in English. Therefore, the recognition system can be supplemented with similar models to support multiple languages.
- This pipeline can also be used for processing handwritten text. It is worth noting that in this case, it is advisable to use Generative Adversarial Network (GAN) [9] to generate training samples, which would allow for the production of very realistic data.
- Large amounts of textual data often require post-processing using natural language processing. For example, machine translation or the division of documents by subject using latent Dirichlet allocation (LDA) [10] could be implemented.
Additionally
[1]
wiki: en.wikipedia.org/wiki/Maximally_stable_extremal_regions
paper: J. Matas, O. Chum, M. Urban, and T. Pajdla. ‘Robust wide baseline stereo from maximally stable extremal regions.’ Proc. of British Machine Vision Conference, pages 384-396, 2002. cmp.felk.cvut.cz/~matas/papers/matas-bmvc02.pdf
[2]
wiki: en.wikipedia.org/wiki/Convolutional_neural_network
paper: LeCun, Yann; Léon Bottou; Yoshua Bengio; Patrick Haffner (1998). ‘Gradient-based learning applied to document recognition’ (PDF). Proceedings of the IEEE. 86 (11): 2278–2324 yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
[3]
wiki: en.wikipedia.org/wiki/Long_short-term_memory
paper: Sepp Hochreiter; Jürgen Schmidhuber (1997). ‘Long short-term memory’. Neural Computation. 9 (8): 1735–1780. www.bioinf.jku.at/publications/older/2604.pdf
[4]
wiki: en.wikipedia.org/wiki/Connectionist_temporal_classification
paper: Graves, Alex; Fernández, Santiago; Gomez, Faustino (2006). ‘Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks’. In Proceedings of the International Conference on Machine Learning, ICML 2006: 369–376. www.cs.toronto.edu/~graves/icml_2006.pdf
[5]
wiki: en.wikipedia.org/wiki/Stochastic_gradient_descent
paper: Diederik, Kingma; Ba, Jimmy (2014). ‘Adam: A method for stochastic optimization’. arxiv.org/pdf/1412.6980.pdf
[6]
wiki: en.wikipedia.org/wiki/Dropout_(neural_networks)
paper: Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever and Ruslan Salakhutdinov. ‘Dropout: A Simple Way to Prevent Neural Networks from Overfitting’. Jmlr.org. Retrieved July 26, 2015. jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf
[7]
wiki: en.wikipedia.org/wiki/Batch_normalization
paper: Ioffe, Sergey; Szegedy, Christian (2015). ‘Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift’ arxiv.org/pdf/1502.03167.pdf
[8]
site: developer.nvidia.com/tensorrt
[9]
wiki: en.wikipedia.org/wiki/Generative_adversarial_network
paper: Goodfellow, Ian; Pouget-Abadie, Jean; Mirza, Mehdi; Xu, Bing; Warde-Farley, David; Ozair, Sherjil; Courville, Aaron; Bengio, Yoshua (2014). Generative Adversarial Networks (PDF). Proceedings of the International Conference on Neural Information Processing Systems (NIPS 2014). pp. 2672–2680. papers.nips.cc/paper/5423-generative-adversarial-nets.pdf
[10]
wiki: en.wikipedia.org/wiki/Latent_Dirichlet_allocation
paper: Blei, David M.; Ng, Andrew Y.; Jordan, Michael I (January 2003). Lafferty, John (ed.). ‘Latent Dirichlet Allocation’. Journal of Machine Learning Research. 3 (4–5): pp. 993–1022. www.jmlr.org/papers/volume3/blei03a/blei03a.pdf